Amazon Ads uses PyTorch, TorchServe, and AWS Inferentia to reduce inference costs by 71% and drive scale out.
Amazon Ads helps companies build their brand and connect with shoppers through ads shown both within and beyond Amazon’s store, including websites, apps, and streaming TV content in more than 15 countries. Businesses and brands of all sizes, including registered sellers, vendors, book vendors, Kindle Direct Publishing (KDP) authors, app developers, and agencies can upload their own ad creatives, which can include images, video, audio, and, of course, products sold on Amazon.

To promote an accurate, safe, and pleasant shopping experience, these ads must comply with content guidelines. For example, ads cannot flash on and off, products must be featured in an appropriate context, and images and text should be appropriate for a general audience. To help ensure that ads meet the required policies and standards, we needed to develop scalable mechanisms and tools.
As a solution, we used machine learning (ML) models to surface ads that might need revision. As deep neural networks flourished over the past decade, our data science team began exploring more versatile deep learning (DL) methods capable of processing text, images, audio, or video with minimal human intervention. To that end, we’ve used PyTorch to build computer vision (CV) and natural language processing (NLP) models that automatically flag potentially non-compliant ads. PyTorch is intuitive, flexible, and user-friendly, and has made our transition to using DL models seamless. Deploying these new models on AWS Inferentia-based Amazon EC2 Inf1 instances, rather than on GPU-based instances, reduced our inference latency by 30 percent and our inference costs by 71 percent for the same workloads.
Transition to deep learning
Our ML systems paired classical models with word embeddings to evaluate ad text. But our requirements evolved, and as the volume of submissions continued to expand, we needed a method nimble enough to scale along with our business. In addition, our models must be fast and serve ads within milliseconds to provide an optimal customer experience.
Over the last decade, DL has become very popular in numerous domains, including natural language, vision, and audio. Because deep neural networks channel data sets through many layers — extracting progressively higher-level features — they can make more nuanced inferences than classical ML models. Rather than simply detecting prohibited language, for example, a DL model can reject an ad for making false claims.
In addition, DL techniques are transferable– a model trained for one task can be adapted to carry out a related task. For instance, a pre-trained neural network can be optimized to detect objects in images and then fine-tuned to identify specific objects that are not allowed to be displayed in an ad.
Deep neural networks can automate two of classical ML’s most time-consuming steps: feature engineering and data labeling. Unlike traditional supervised learning approaches, which require exploratory data analysis and hand-engineered features, deep neural networks learn the relevant features directly from the data. DL models can also analyze unstructured data, like text and images, without the preprocessing necessary in ML. Deep neural networks scale effectively with more data and perform especially well in applications involving large data sets.
We chose PyTorch to develop our models because it helped us maximize the performance of our systems. With PyTorch, we can serve our customers better while taking advantage of Python’s most intuitive concepts. The programming in PyTorch is object-oriented: it groups processing functions with the data they modify. As a result, our codebase is modular, and we can reuse pieces of code in different applications. In addition, PyTorch’s eager mode allows loops and control structures and, therefore, more complex operations in the model. Eager mode makes it easy to prototype and iterate upon our models, and we can work with various data structures. This flexibility helps us update our models quickly to meet changing business requirements.
“Before this, we experimented with other frameworks that were “Pythonic,” but PyTorch was the clear winner for us here.” said Yashal Kanungo, Applied Scientist. “Using PyTorch was easy because the structure felt native to Python programming, which the data scientists were very familiar with”.
Training pipeline
Today, we build our text models entirely in PyTorch. To save time and money, we often skip the early stages of training by fine-tuning a pre-trained NLP model for language analysis. If we need a new model to evaluate images or video, we start by browsing PyTorch’s torchvision library, which offers pretrained options for image and video classification, object detection, instance segmentation, and pose estimation. For specialized tasks, we build a custom model from the ground up. PyTorch is perfect for this, because eager mode and the user-friendly front end make it easy to experiment with different architectures.
To learn how to finetune neural networks in PyTorch, head to this tutorial.
Before we begin training, we optimize our model’s hyperparameters, the variables that define the network architecture (for example, the number of hidden layers) and training mechanics (such as learning rate and batch size). Choosing appropriate hyperparameter values is essential, because they will shape the training behavior of the model. We rely on the Bayesian search feature in SageMaker, AWS’s ML platform, for this step. Bayesian search treats hyperparameter tuning as a regression problem: It proposes the hyperparameter combinations that are likely to produce the best results and runs training jobs to test those values. After each trial, a regression algorithm determines the next set of hyperparameter values to test, and performance improves incrementally.
We prototype and iterate upon our models using SageMaker Notebooks. Eager mode lets us prototype models quickly by building a new computational graph for each training batch; the sequence of operations can change from iteration to iteration to accommodate different data structures or to jibe with intermediate results. That frees us to adjust the network during training without starting over from scratch. These dynamic graphs are particularly valuable for recursive computations based on variable sequence lengths, such as the words, sentences, and paragraphs in an ad that are analyzed with NLP.
When we’ve finalized the model architecture, we deploy training jobs on SageMaker. PyTorch helps us develop large models faster by running numerous training jobs at the same time. PyTorch’s Distributed Data Parallel (DDP) module replicates a single model across multiple interconnected machines within SageMaker, and all the processes run forward passes simultaneously on their own unique portion of the data set. During the backward pass, the module averages the gradients of all the processes, so each local model is updated with the same parameter values.
Model deployment pipeline
When we deploy the model in production, we want to ensure lower inference costs without impacting prediction accuracy. Several PyTorch features and AWS services have helped us address the challenge.
The flexibility of a dynamic graph enriches training, but in deployment we want to maximize performance and portability. An advantage of developing NLP models in PyTorch is that out of the box, they can be traced into a static sequence of operations by TorchScript, a subset of Python specialized for ML applications. Torchscript converts PyTorch models to a more efficient, production-friendly intermediate representation (IR) graph that is easily compiled. We run a sample input through the model, and TorchScript records the operations executed during the forward pass. The resulting IR graph can run in high-performance environments, including C++ and other multithreaded Python-free contexts, and optimizations such as operator fusion can speed up the runtime.
Neuron SDK and AWS Inferentia powered compute
We deploy our models on Amazon EC2 Inf1 instances powered by AWS Inferentia, Amazon’s first ML silicon designed to accelerate deep learning inference workloads. Inferentia has shown to reduce inference costs by up to 70% compared to Amazon EC2 GPU-based instances. We used the AWS Neuron SDK — a set of software tools used with Inferentia — to compile and optimize our models for deployment on EC2 Inf1 instances.
The code snippet below shows how to compile a Hugging Face BERT model with Neuron. Like torch.jit.trace(), neuron.trace() records the model’s operations on an example input during the forward pass to build a static IR graph.
import torch
from transformers import BertModel, BertTokenizer
import torch.neuron
tokenizer = BertTokenizer.from_pretrained("path to saved vocab")
model = BertModel.from_pretrained("path to the saved model", returned_dict=False)
inputs = tokenizer ("sample input", return_tensor="pt")
neuron_model = torch.neuron.trace(model,
example_inputs = (inputs['input_ids'], inputs['attention_mask']),
verbose = 1)
output = neuron_model(*(inputs['input_ids'], inputs['attention_mask']))
Autocasting and recalibration
Under the hood, Neuron optimizes our models for performance by autocasting them to a smaller data type. As a default, most applications represent neural network values in the 32-bit single-precision floating point (FP32) number format. Autocasting the model to a 16-bit format — half-precision floating point (FP16) or Brain Floating Point (BF16) — reduces a model’s memory footprint and execution time. In our case, we decided to use FP16 to optimize for performance while maintaining high accuracy.
Autocasting to a smaller data type can, in some cases, trigger slight differences in the model’s predictions. To ensure that the model’s accuracy is not affected, Neuron compares the performance metrics and predictions of the FP16 and FP32 models. When autocasting diminishes the model’s accuracy, we can tell the Neuron compiler to convert only the weights and certain data inputs to FP16, keeping the rest of the intermediate results in FP32. In addition, we often run a few iterations with the training data to recalibrate our autocasted models. This process is much less intensive than the original training.
Deployment
To analyze multimedia ads, we run an ensemble of DL models. All ads uploaded to Amazon are run through specialized models that assess every type of content they include: images, video and audio, headlines, texts, backgrounds, and even syntax, grammar, and potentially inappropriate language. The signals we receive from these models indicate whether or not an advertisement complies with our criteria.
Deploying and monitoring multiple models is significantly complex, so we depend on TorchServe, SageMaker’s default PyTorch model serving library. Jointly developed by Facebook’s PyTorch team and AWS to streamline the transition from prototyping to production, TorchServe helps us deploy trained PyTorch models at scale without having to write custom code. It provides a secure set of REST APIs for inference, management, metrics, and explanations. With features such as multi-model serving, model versioning, ensemble support, and automatic batching, TorchServe is ideal for supporting our immense workload. You can read more about deploying your Pytorch models on SageMaker with native TorchServe integration in this blog post.
In some use cases, we take advantage of PyTorch’s object-oriented programming paradigm to wrap multiple DL models into one parent object — a PyTorch nn.Module — and serve them as a single ensemble. In other cases, we use TorchServe to serve individual models on separate SageMaker endpoints, running on AWS Inf1 instances.
Custom handlers
We particularly appreciate that TorchServe allows us to embed our model initialization, preprocessing, inferencing, and post processing code in a single Python script, handler.py, which lives on the server. This script — the handler —preprocesses the un-labeled data from an ad, runs that data through our models, and delivers the resulting inferences to downstream systems. TorchServe provides several default handlers that load weights and architecture and prepare the model to run on a particular device. We can bundle all the additional required artifacts, such as vocabulary files or label maps, with the model in a single archive file.
When we need to deploy models that have complex initialization processes or that originated in third-party libraries, we design custom handlers in TorchServe. These let us load any model, from any library, with any required process. The following snippet shows a simple handler that can serve Hugging Face BERT models on any SageMaker hosting endpoint instance.
import torch
import torch.neuron
from ts.torch_handler.base_handler import BaseHandler
import transformers
from transformers import AutoModelForSequenceClassification,AutoTokenizer
class MyModelHandler(BaseHandler):
def initialize(self, context):
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
serialized_file = self.manifest["model"]["serializedFile"]
model_pt_path = os.path.join(model_dir, serialized_file)
self.tokenizer = AutoTokenizer.from_pretrained(
model_dir, do_lower_case=True
)
self.model = AutoModelForSequenceClassification.from_pretrained(
model_dir
)
def preprocess(self, data):
input_text = data.get("data")
if input_text is None:
input_text = data.get("body")
inputs = self.tokenizer.encode_plus(input_text, max_length=int(max_length), pad_to_max_length=True, add_special_tokens=True, return_tensors='pt')
return inputs
def inference(self,inputs):
predictions = self.model(**inputs)
return predictions
def postprocess(self, output):
return output
Batching
Hardware accelerators are optimized for parallelism, and batching — feeding a model multiple inputs in a single step — helps saturate all available capacity, typically resulting in higher throughputs. Excessively high batch sizes, however, can increase latency with minimal improvement in throughputs. Experimenting with different batch sizes helps us identify the sweet spot for our models and hardware accelerator. We run experiments to determine the best batch size for our model size, payload size, and request traffic patterns.
The Neuron compiler now supports variable batch sizes. Previously, tracing a model hardcoded the predefined batch size, so we had to pad our data, which can waste compute, slow throughputs, and exacerbate latency. Inferentia is optimized to maximize throughput for small batches, reducing latency by easing the load on the system.
Parallelism
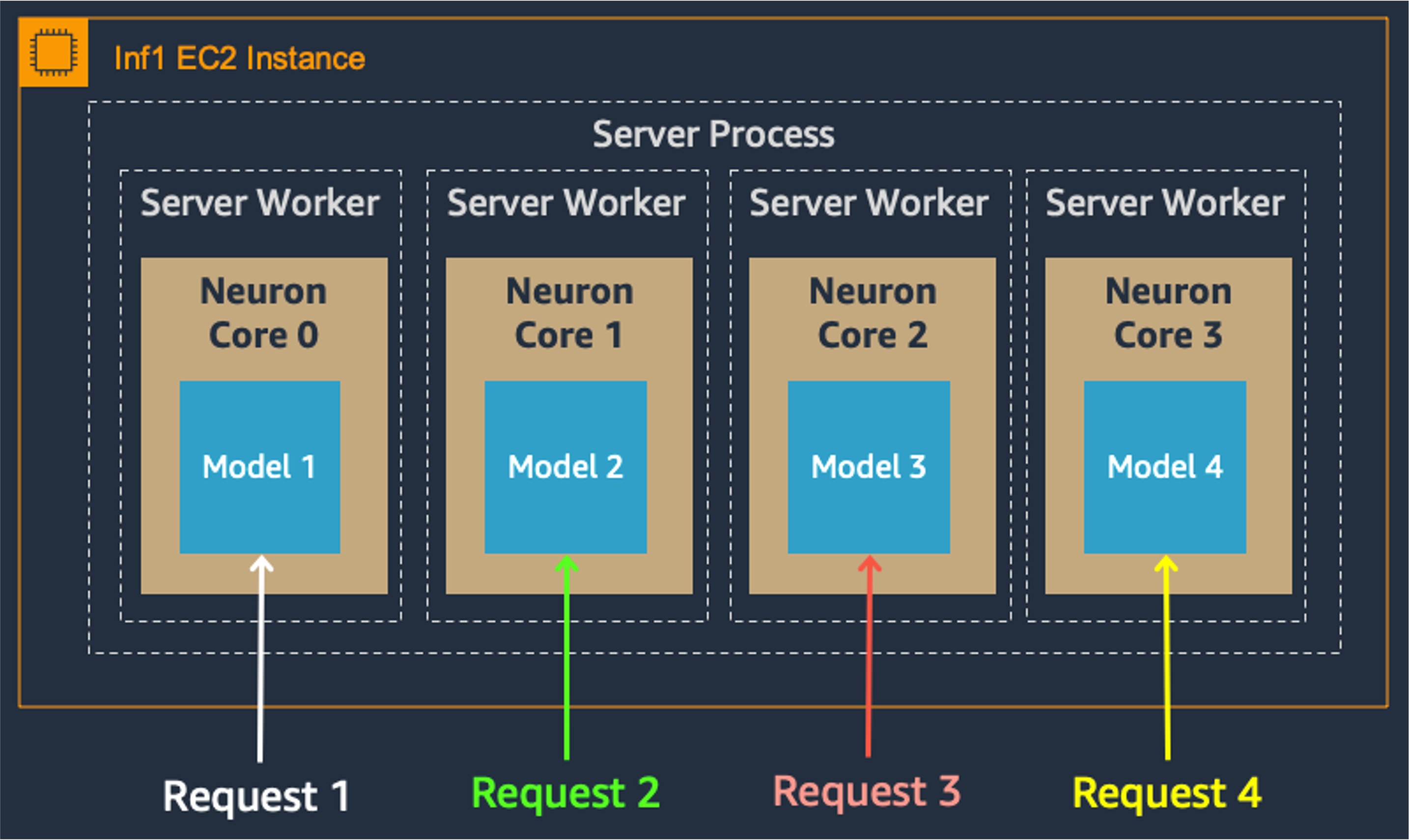
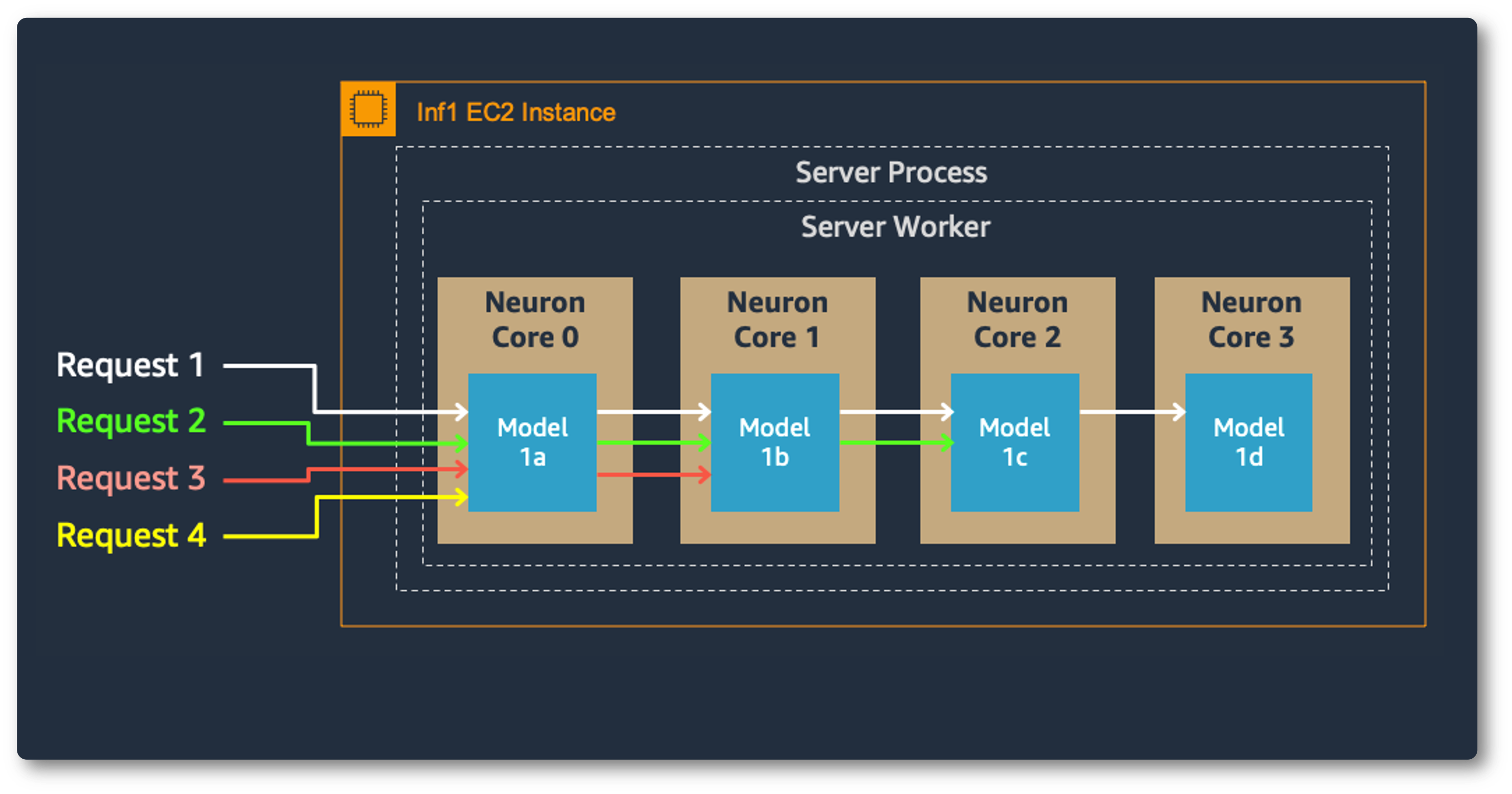
Model parallelism on multi-cores also improves throughput and latency, which is crucial for our heavy workloads. Each Inferentia chip contains four NeuronCores that can either run separate models simultaneously or form a pipeline to stream a single model. In our use case, the data parallel configuration offers the highest throughput at the lowest cost, because it scales out concurrent processing requests.
Data Parallel:
Model Parallel:
Monitoring
It is critical that we monitor the accuracy of our inferences in production. Models that initially make good predictions can eventually degrade in deployment as they are exposed to a wider variety of data. This phenomenon, called model drift, usually occurs when the input data distributions or the prediction targets change.
We use SageMaker Model Monitor to track parity between the training and production data. Model Monitor notifies us when predictions in production begin to deviate from the training and validation results. Thanks to this early warning, we can restore accuracy — by retraining the model if necessary — before our advertisers are affected. To track performance in real time, Model Monitor also sends us metrics about the quality of predictions, such as accuracy, F-scores, and the distribution of the predicted classes.
To determine if our application needs to scale, TorchServe logs resource utilization metrics for the CPU, Memory, and Disk at regular intervals; it also records the number of requests received versus the number served. For custom metrics, TorchServe offers a Metrics API.
A rewarding result
Our DL models, developed in PyTorch and deployed on Inferentia, sped up our ads analysis while cutting costs. Starting with our first explorations in DL, programming in PyTorch felt natural. Its user-friendly features helped smooth the course from our early experiments to the deployment of our multimodal ensembles. PyTorch lets us prototype and build models quickly, which is vital as our advertising service evolves and expands. For an added benefit, PyTorch works seamlessly with Inferentia and our AWS ML stack. We look forward to building more use cases with PyTorch, so we can continue to serve our clients accurate, real-time results.
